前言
本系列尽量不涉及太多专业知识,更加偏向于实际操作,最终带大家能够实际创建一个属于自己的 AI 智能体。
大语言模型(Large Language Model, LLM)是自然语言处理(NLP)领域的重要技术成果。目前我们所使用的各种 AI 应用,如 ChatGPT、DeepSeek 等,其核心功能主要基于 LLM 技术实现。它们通过在大规模文本数据上进行训练,能够理解和生成符合人类语言习惯的文本。Transformer 架构是 LLM 实现的核心技术基础,从 Transformer 架构提出至今,LLM 已经历了多个重要的发展阶段。
现在本文将揭开 LLM 的神秘面纱,带你了解它的基本原理和应用。
LLM 的本质:一个 “超级预测机”
简单说,LLM 的所做的事情很简单并且一直都没有变化,就是预测 “下一个词该是什么”。 比如你输入 “今天天气很好,我想出去”,它会预测下一个词可能是 “玩”“散步”“逛街” 等——而整个句子、段落甚至文章,就是这样一个个 “下一个词” 叠加出来的结果。LLM 在训练的时候通过互联网上海量级的文本数据进行训练,能够理解和生成符合人类语言习惯的文本。
但是这个过程说起来很简单,但是中间会遇到很多的挑战,比如:
- 如何表示语言:世界上的语言和文字有很多,光是中文就有成千上万的字和词,如何把它们转换成计算机能理解的形式?
- 如何理解上下文:同一个词在不同的句子中可能有不同的意思,如何让模型理解上下文?
- 如何理解词语之间的关系:词与词之间存在逻辑关系,比如“树木” 和 “绿叶” 之间的关系,如何让模型理解这些关系?
- 如何处理长文本:人类的语言是连续的,如何让模型处理长文本而不丢失信息?
LLM 的学习过程,其实是在海量文本中找 “规律”。具体分两步:
1. 先把语言拆成 “最小单位”—— tokens(词块)
人类语言有字、词、句子,但计算机看不懂,所以要先把文本拆成一个个 “小积木”(tokens)。Token 和词组并不完全等同,它可以是一个字、一个词,甚至是一个词的一部分。
比如 “我爱吃苹果”,可能会拆成 [我,爱,吃,苹果] 这 4 个 tokens;复杂点的词可能拆得更细,比如 “人工智能” 可能拆成 [人工,智能]。 这样一来,计算机就能用数字给每个 token 编个号(比如 “我”=1001,“爱”=2002),方便后续计算。
我们可以前往 Tiktokenizer 来更加直观的看到 token 的拆分方式。
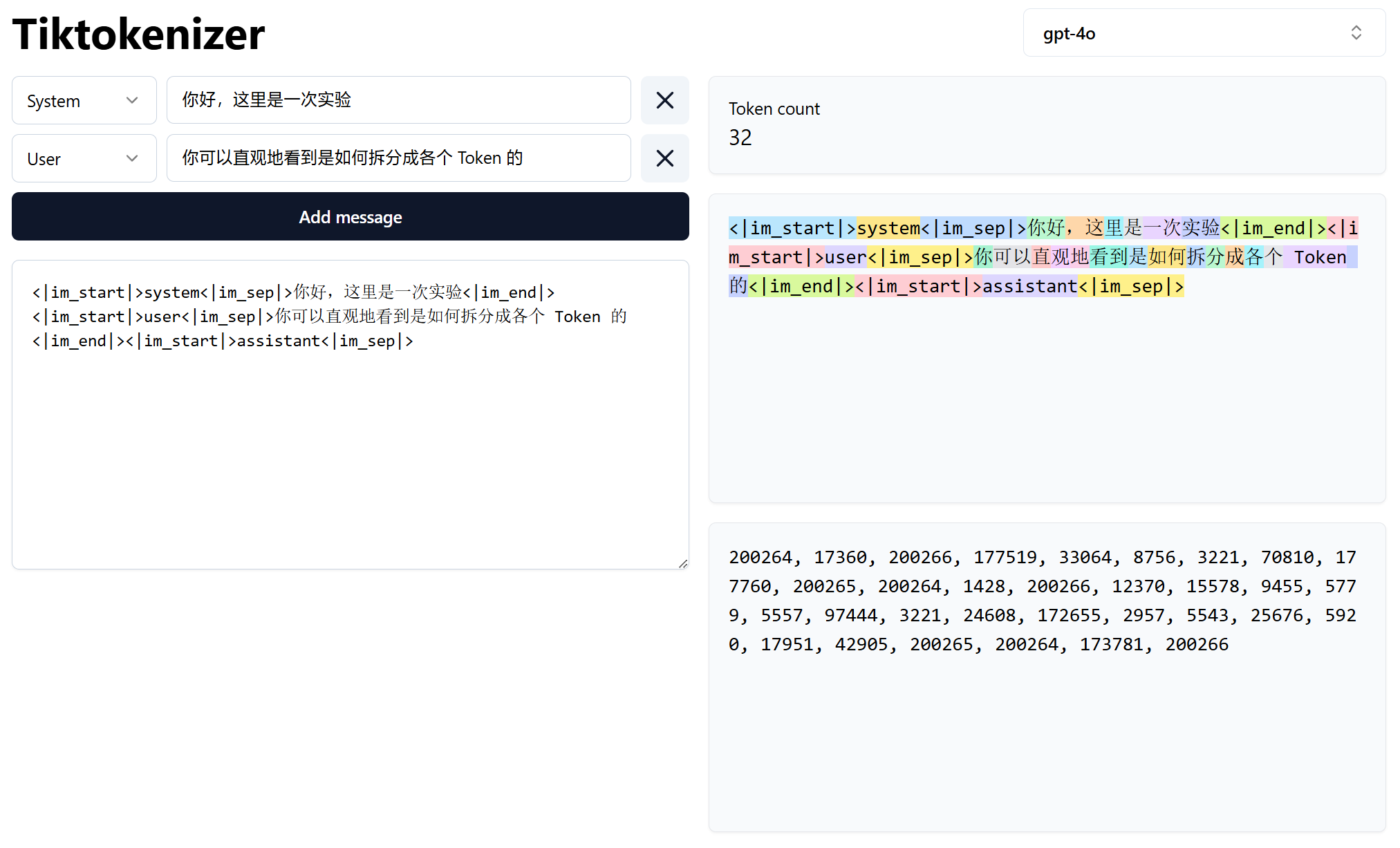
相信你已经看到了图片中存在的很多奇怪的一些标记,比如 <|endoftext|>,它们是一些特殊的标记,用来表示文本的开始、结束或者其他特定含义。
每一个 Token 都被转换成了一串数字 (实际是一个高维向量),机器就能够通过这些数字来处理文本了。这一串数字并不是随机的,它能够通过统计来将词语之间的逻辑关系表现在向量的运算之中。这项技术称为 Word2Vec 或者更广义的词嵌入(Word Embedding)。
例如在论文中提到的经典例子是 “国王 - 男人 + 女人 = 女王”,每一个词的逻辑关系可以通过他们所对应的的向量运算得到。这里的向量的值实际上是通过统计大量文本中 “国王” 和 “女王” 的出现频率来确定的。同时我们也可以很直观的理解到,意思相近的词,他们的向量也会比较接近。
这样每一个词语转化成的向量就有了一个 “语义坐标”,所有词都分布在这个高维空间里,相关的词聚在同一区域。
2. 在海量文本中算 “概率”:谁和谁经常一起出现?
假设 LLM 读了 100 万句话,发现:
- 当出现 “下雨天” 时,后面跟着 “要带伞” 的概率是 30%,跟着 “路滑” 的概率是 25%,跟着 “吃火锅” 的概率是 5%……
- 当出现 “我想喝” 时,后面跟着 “水” 的概率是 40%,“咖啡” 是 20%,“奶茶” 是 15%……
这些 “谁和谁经常一起出现” 的概率,就是 LLM 学到的 “规律”。学的文本越多,它掌握的 “概率规律” 就越全。
关键技术:Transformer(转换器)—— 让它能 “理解上下文”
光靠简单的 “相邻词概率” 还不够。比如 “他喜欢打篮球,它很有趣”,这里的 “它” 指的是 “篮球”,但如果只看 “它” 前面的词 “,”,就无法理解。这时候需要一个能 “看更远上下文” 的工具 ——Transformer,这是现在 LLM 的核心结构,2017 年被提出。 论文链接: Attention is All You Need
Transformer 的关键能力是 “注意力机制”(Attention),可以理解为:
当预测某个词时,它会 “重点看” 上下文里和这个词关系最密切的部分。 比如上面的例子,预测 “它” 时,注意力机制会让模型 “注意” 到前面的 “篮球”,从而判断 “它” 指的是篮球。
这就像我们读句子时,看到 “他”“她”“它”,会自动联系前文找指代对象 ——Transformer 让模型也具备了类似的 “上下文理解” 能力。
对每个词(如 “它”),会生成三个向量:
- Query(查询):“我想找和我相关的词”;
- Key(键):“每个词的‘标签’,方便被查询匹配”;
- Value(值):“每个词的‘内容’,被选中后要传递的信息”。
然后,“它” 的 Query 会和所有词的 Key 计算 “相似度”,得到每个词对 “它” 的 “关注度分数”(比如 “猫” 0.2 分,“狗” 0.7 分,其他词 0.1 分)。之后,根据关注度分数,对所有词的 Value 向量进行加权求和,就能够得到 “它” 的上下文信息。
训练过程:先 “学通用规律”,再 “学具体任务”
LLM 的 “成长” 分两个阶段:
1. 预训练(Pre-training):喂海量文本,学 “通用语言规律”
开发者会收集互联网上的海量文本(书籍、网页、小说、论文等,可能有几千亿甚至几万亿个 tokens),让模型在这些文本中反复学习 “预测下一个词”。 这个阶段,模型就像在 “读遍天下书”,掌握了通用的语言逻辑、常识(比如 “太阳从东边升起”“人要吃饭”)、语法规则等。
2. 微调(Fine-tuning):针对具体场景 “补课”
预训练后的模型可能太 “通用”,比如需要它当客服,就得用 “客服对话样本” 再训练它 —— 让它知道面对 “退款怎么操作”,应该优先回答流程,而不是扯别的。 这个阶段就像 “专项培训”,让模型在特定场景下更 “懂规矩”。
为什么它能 “看起来像理解意思”?其实是 “模式匹配” 的极致
LLM 本质上是在做 “超级复杂的模式匹配”:它见过的文本里,类似的问题、类似的语境下,人类通常会说什么,它就模仿着说出来。
比如你问 “为什么天是蓝的?”,它不是真的 “理解” 了光学原理,而是因为在训练文本中,这个问题后面经常跟着 “因为大气散射蓝光” 之类的答案,所以它会预测出这些词。
这也是为什么 LLM 有时会 “一本正经地胡说八道”:如果某个错误答案在训练文本中出现过很多次(比如谣言),它也会因为 “概率高” 而预测出来。
总结
LLM 的核心就是 “预测下一个词”,通过海量文本学习语言规律,使用 Transformer 架构理解上下文。它的强大在于能模仿人类语言习惯,但本质上仍是 “模式匹配”。
目前其发展面临诸多问题,比如规模与效率存在矛盾,幻觉现象难以根治,训练数据在质量、多样性及时效性上有挑战,可解释性差,存在伦理与偏见问题,多模态能力融合也不足,不过这些问题正推动着技术不断进步,助力 LLM 向更高效、可靠、智能的方向发展。
原创:Kengwang 编辑:GoForth
引申阅读
仅是作为引申阅读
- Attention is All You Need - Transformer 论文
- The Illustrated Transformer - 直观的 Transformer 介绍
- LLMs发展史:从Transformer(2017)到DeepSeek-R1(2025)