相信大家学习每一门编程语言都是从输出一句“Hello World”开始,用来建立你与计算机的第一次连接。而作为计算机程序的“基石”——算法,你的第一个“Hello World”无疑就是时间复杂度这个东西了。
什么是时间复杂度?
时间复杂度(Time Complexity)直译就是运行程序所花时间的复杂程度。说白了,一个程序运行的快不快就取决于时间复杂度。越复杂的东西花的时间自然久,我们的时间都是很宝贵的,自然想让程序越快越好(你总不想进度条总是在99%吧),也就是时间复杂度越小越好!
俗话说的好“没有最好,只有更好”,那我们如何去找到一个程序的时间复杂度呢?因为实际运行时间会受到机器性能、编程语言、编译器优化等多种外部因素的影响,而是专注于分析时间消耗随数据量增长的“速度级别”或“数量级”。因为每一次的测试数据都一定尽如人意,那不如就让最差的情况来表示这个程序的复杂度———我们给他一个名字最差(大)时间复杂度这种度量方式通常使用大O符号(表示为O(...))来形式化表达,括号内的函数描述了算法运行时间如何随着输入规模n的扩大而变化。例如,O(n)表示算法的执行时间与输入规模n成线性比例关系。
但是我们会有一个疑问,如果只考虑最差情况,那有一些算法的优点很可能就被埋没了,所以当O(...)相同时,我们应该进一步考虑平均时间复杂度。但是大家平时看到的时间复杂度O(...)基本都是考虑了最差情况和平均情况的,这更像是一种概率分布。
常见的最差时间复杂度O(...)情况
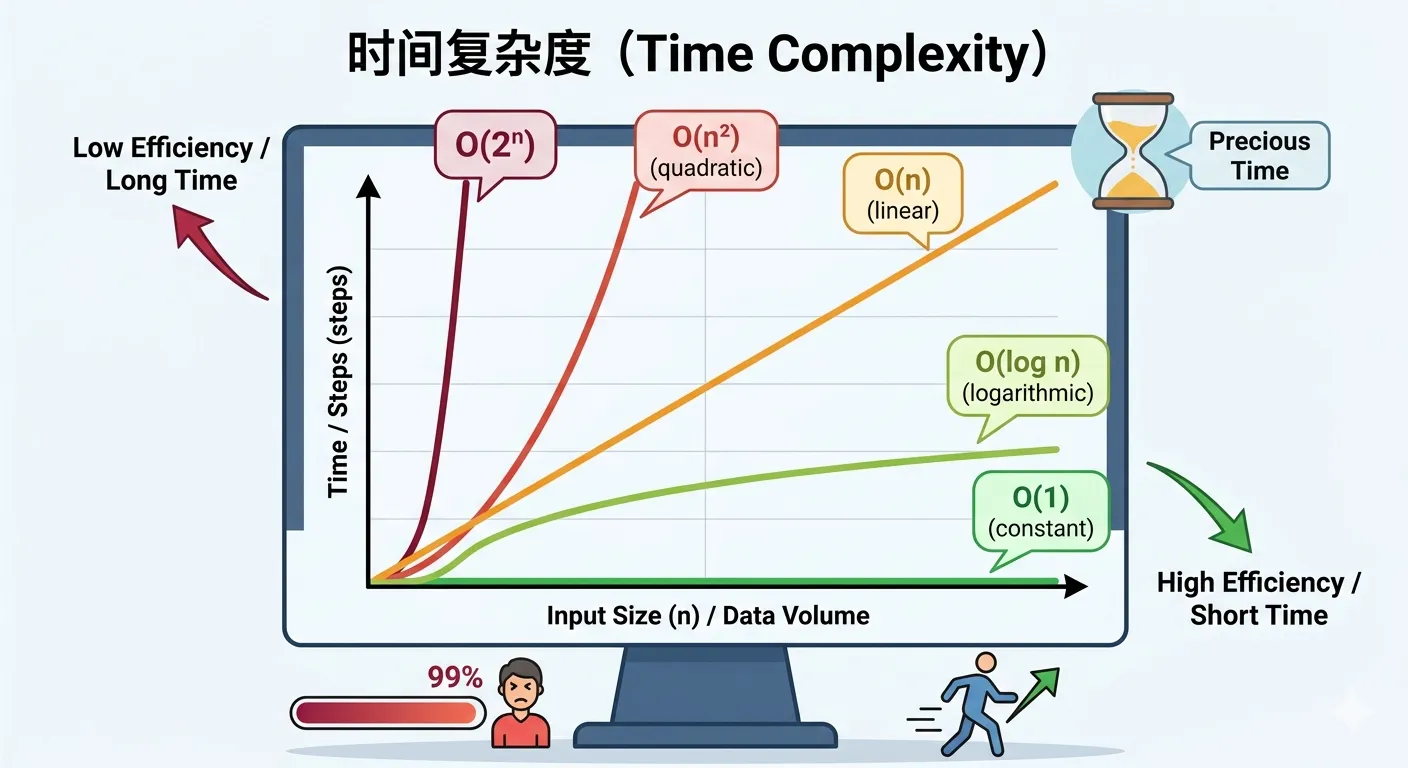
常见的时间复杂度类别按照效率从高到低(即执行时间增长从慢到快)排列如下:
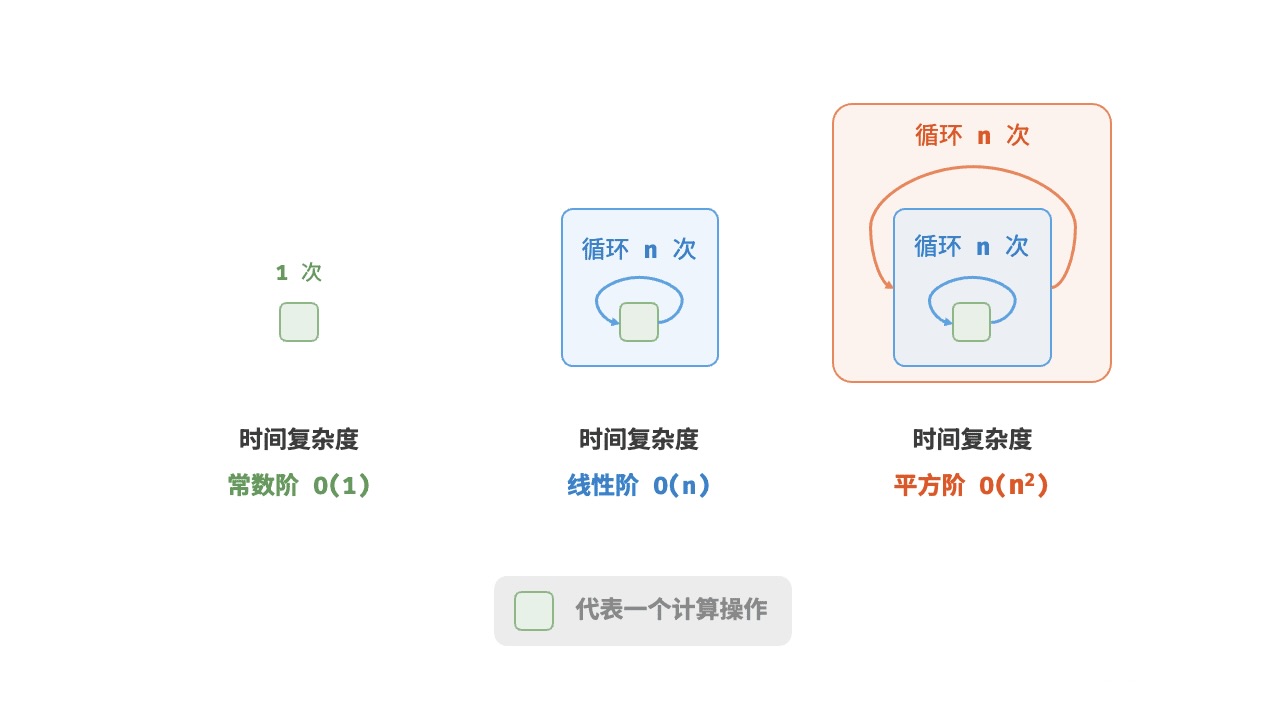
O(1) 常数时间复杂度
算法的执行时间不随输入数据规模n的变化而改变。例如,访问数组中特定下标的元素(如arr[5]),无论数组长度n是10还是1000,通过索引定位元素的操作仅需一步;执行栈的压入(push)或弹出(pop)操作,只需直接操作栈顶元素,与栈内元素总数无关;判断一个数是否为偶数(通过取模运算n%2),无论n的大小,计算过程仅需固定步骤。
def get_from_dict(dictionary, key):
return dictionary.get(key, "Not found")
my_dict = {"a": 1, "b": 2, "c": 3}
value = get_from_dict(my_dict, "b")O(n) 线性时间复杂度
算法的运行时间与输入规模n成正比。常见于需要遍历整个数据结构的操作,如逐个扫描数组或链表中的元素。
def linear_search(lst, target):
for i, element in enumerate(lst):
if element == target:
return i
return -1
names = ["Alice", "Bob", "Charlie", "David", "Eve"]
target_name = "Charlie"
index = linear_search(names, target_name)
print(f"找到 '{target_name}' 在索引 {index}")
O(n²) 平方时间复杂度
运行时间与n的平方成正比,常见于两层循环嵌套的算法,如冒泡排序、选择排序、插入排序,以及遍历二维数组的所有元素。
def selection_sort(arr):
n = len(arr)
for i in range(n):
min_idx = i
for j in range(i + 1, n):
if arr[j] < arr[min_idx]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i]
return arr
numbers = [64, 25, 12, 22, 11]
sorted_numbers = selection_sort(numbers.copy())
print(f"原始数组: {numbers}")
print(f"排序后: {sorted_numbers}")
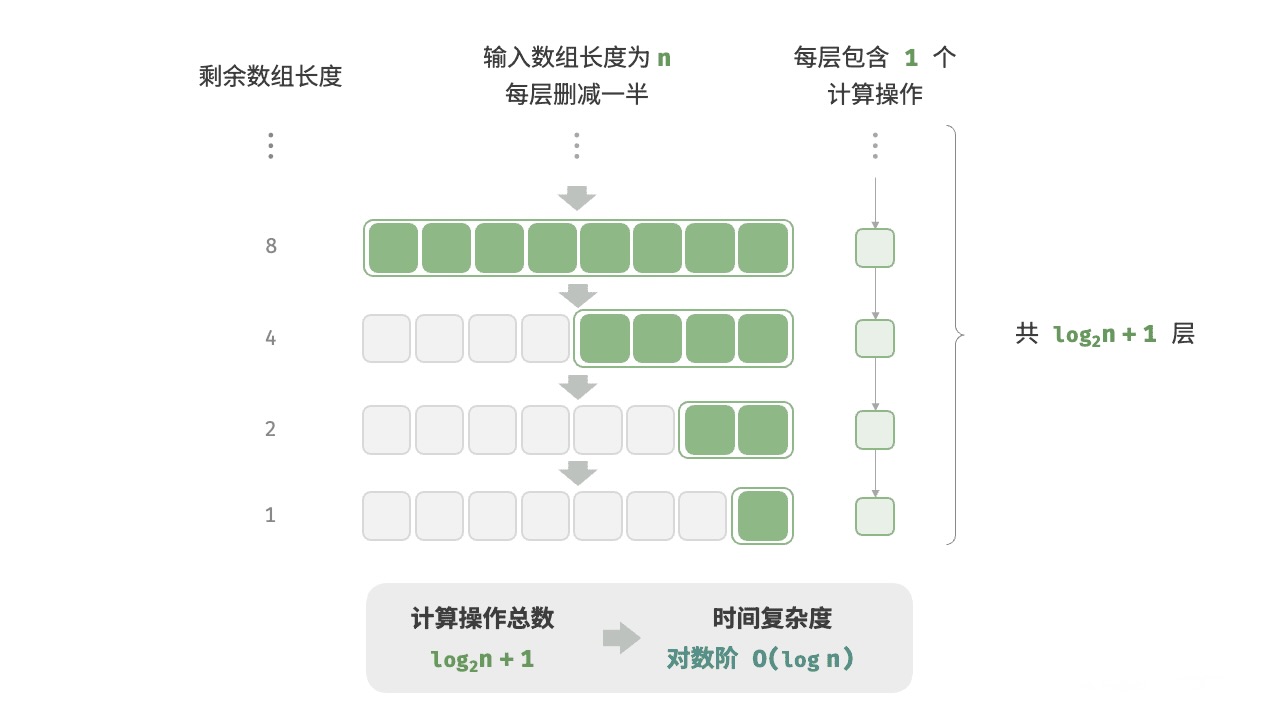
O(log n) 对数时间复杂度
以2为底n的对数,在书写时通常省略2,直接写作(log n)。随着n的增大,执行时间增长极为缓慢。典型例子是二分查找算法,它通过不断将搜索区间减半来快速定位目标。
def binary_search(arr, target):
left = 0
right = arr.len()
while(l <= r){
mid = left + (right - left)/2
if (arr[mid] == target) {
return true;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
return false
}
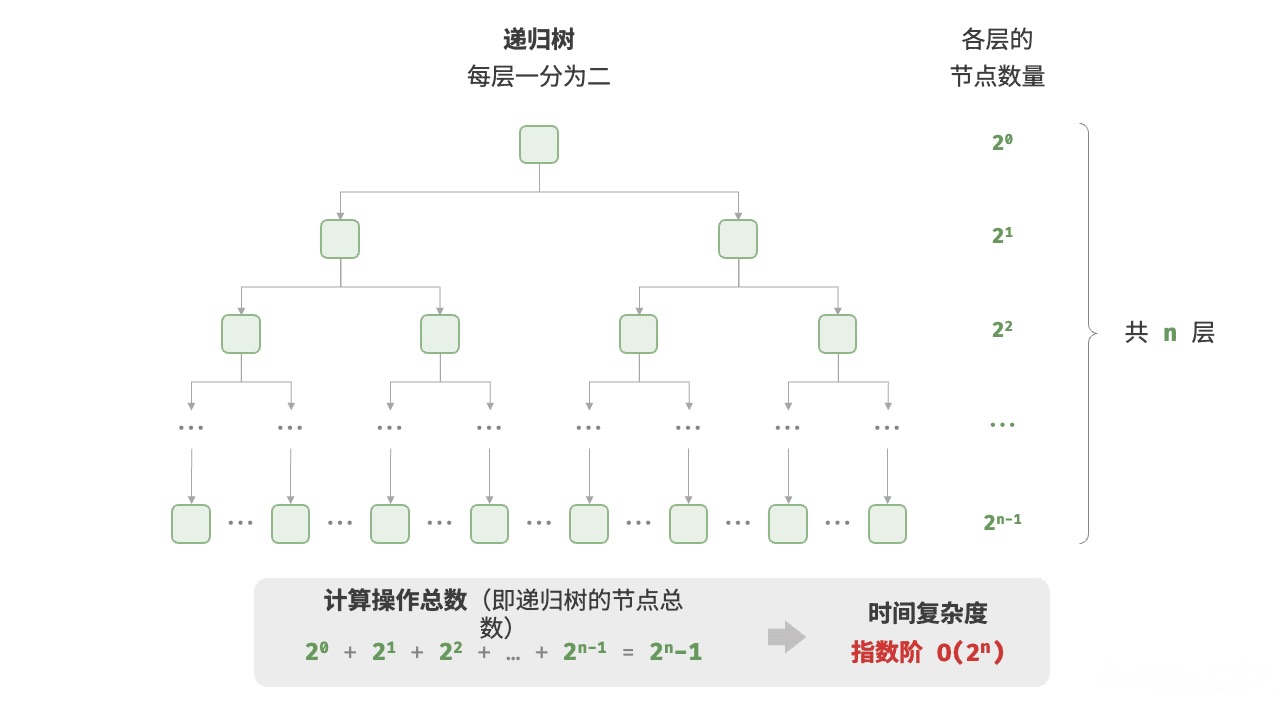
O(2ⁿ) 指数时间复杂度
执行时间随n增长呈指数级上升,这类算法通常在实际应用中难以处理较大规模数据。例如,未优化的递归计算斐波那契数列,或暴力求解旅行商问题。
O(n!) 阶乘时间复杂度
增长速率最快,在实际中几乎不可行,通常出现在需要处理所有排列组合的问题中,如暴力破解某些组合优化问题。
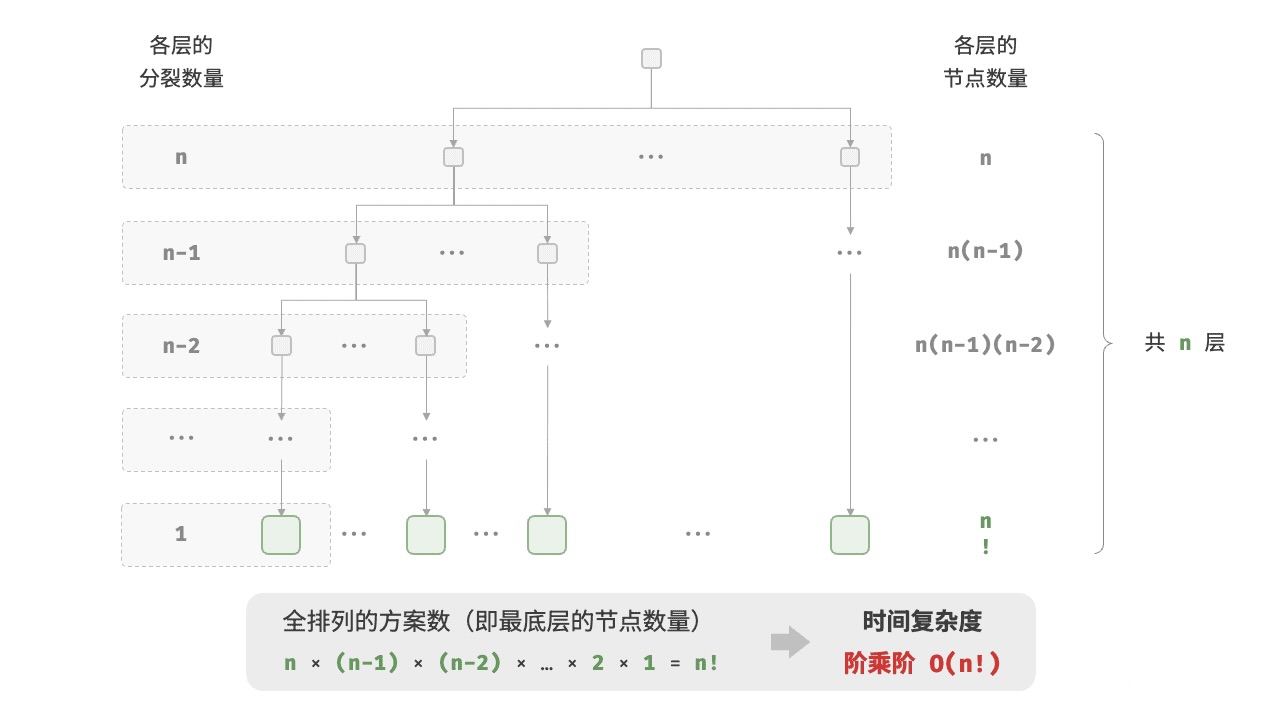
算法的设计与选择需综合考虑时间复杂度和空间复杂度(即内存占用)。由于计算时间和存储空间在物理上都是有限资源,开发人员常需根据具体应用场景在二者之间进行权衡,决定是采用“以时间换空间”还是“以空间换时间”的策略,以求在特定约束下达到最优的整体性能。
原创:吴邹辰 编辑:GoForth、Anka