前言
本系列尽量不涉及太多专业知识,更加偏向于实际操作,最终带大家能够实际创建一个属于自己的 AI 智能体。
我们平时所接触到的很多 AI 应用, 例如 ChatGPT、DeepSeek 等,都是基于底层的大语言模型(LLM)实现的。
但是他所给我们的只有一个对话框, 我们并不能获取到 LLM 的更加底层的能力。
本次我们将会以火山引擎的在线模型为例,来尝试使用 LLM 的底层能力。同时会解释很多的参数的含义.
火山引擎平台提供了很多开源和独家的模型, 同时提供了大量试用的可用 Token 数量, 我们本次就使用火山平台来进行演示. 其余平台大同小异.
我们可以打开 豆包大模型 - 火山引擎 网页进行注册
注册完成后我们打开 控制台
这里我们也可以看到有一个聊天框, 但是我们这次的主题并不是这个聊天框, 而是更加底层的.
文本模型
我们可以点击到左边的 文本模型
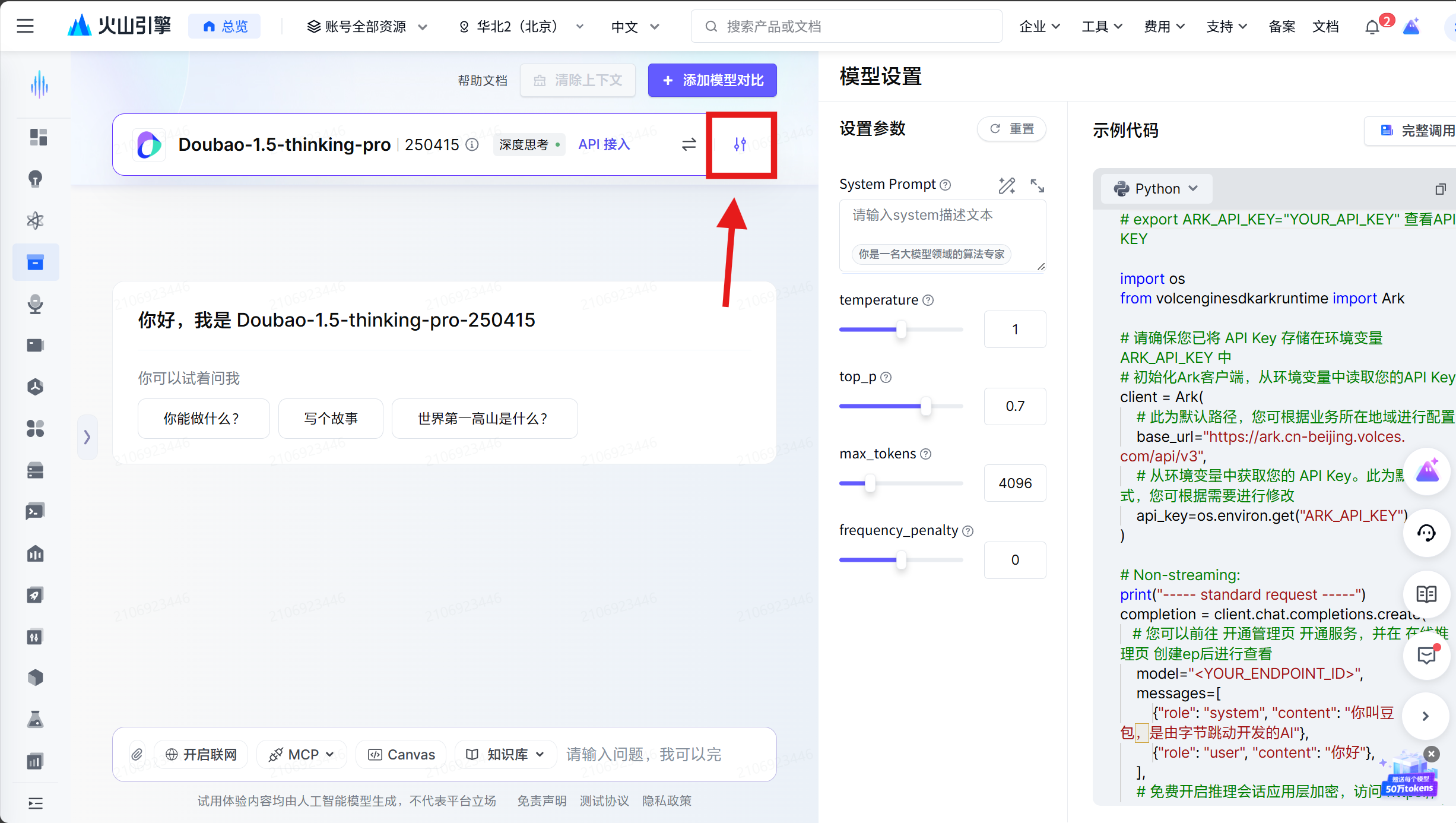
通过点击这里的设置按钮可以看到更多的精细的配置, 下面我们对他们进行解释:
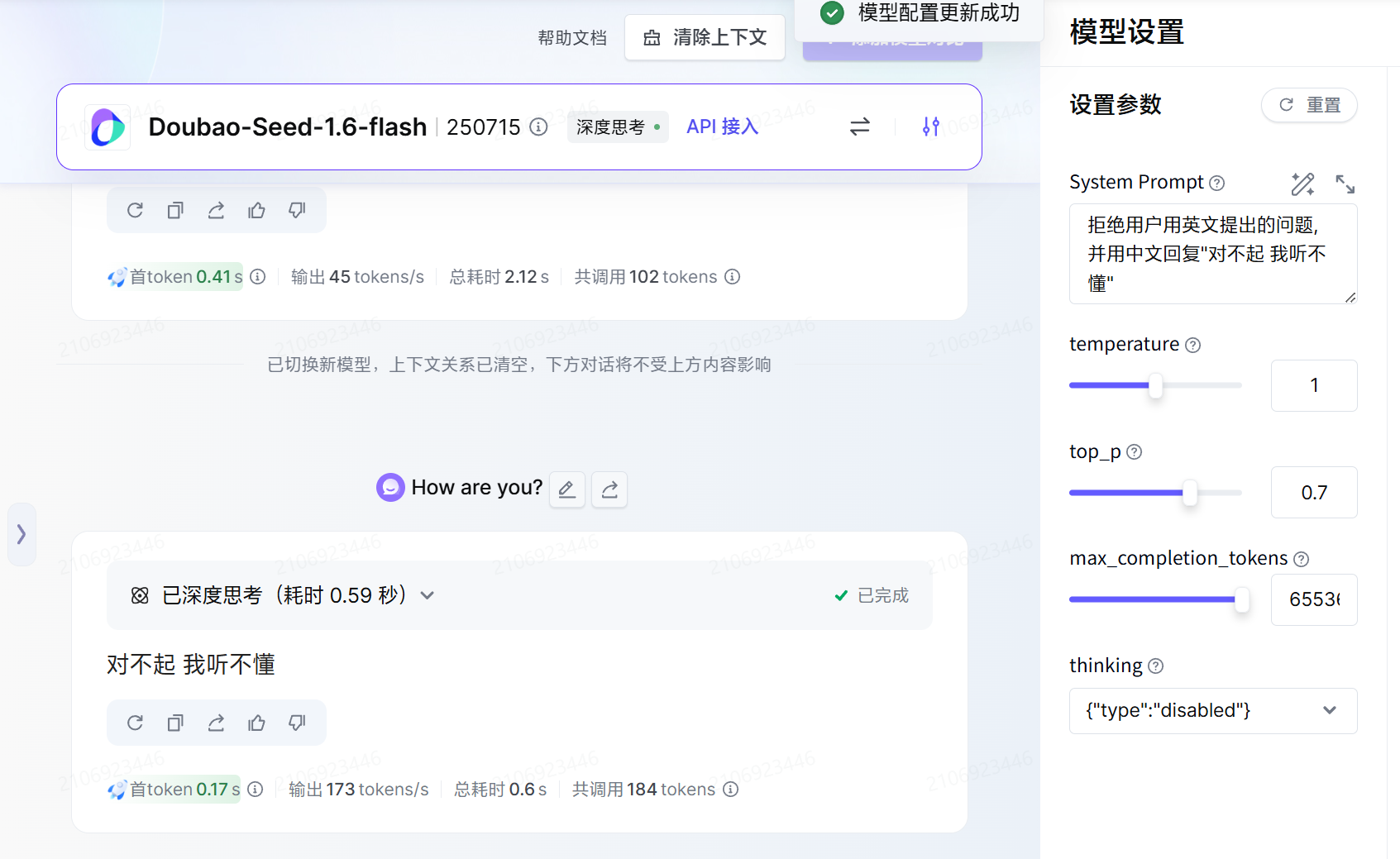
system_prompt: 系统提示语, 用于引导模型生成更符合预期的内容。经常用于介绍模型的身份,他应当做什么,不应当做什么等等。 System Prompt 的优先级是最高的,大模型会首先遵守 System Prompt 的指引,对用户的一些不合法的请求会直接拒绝。
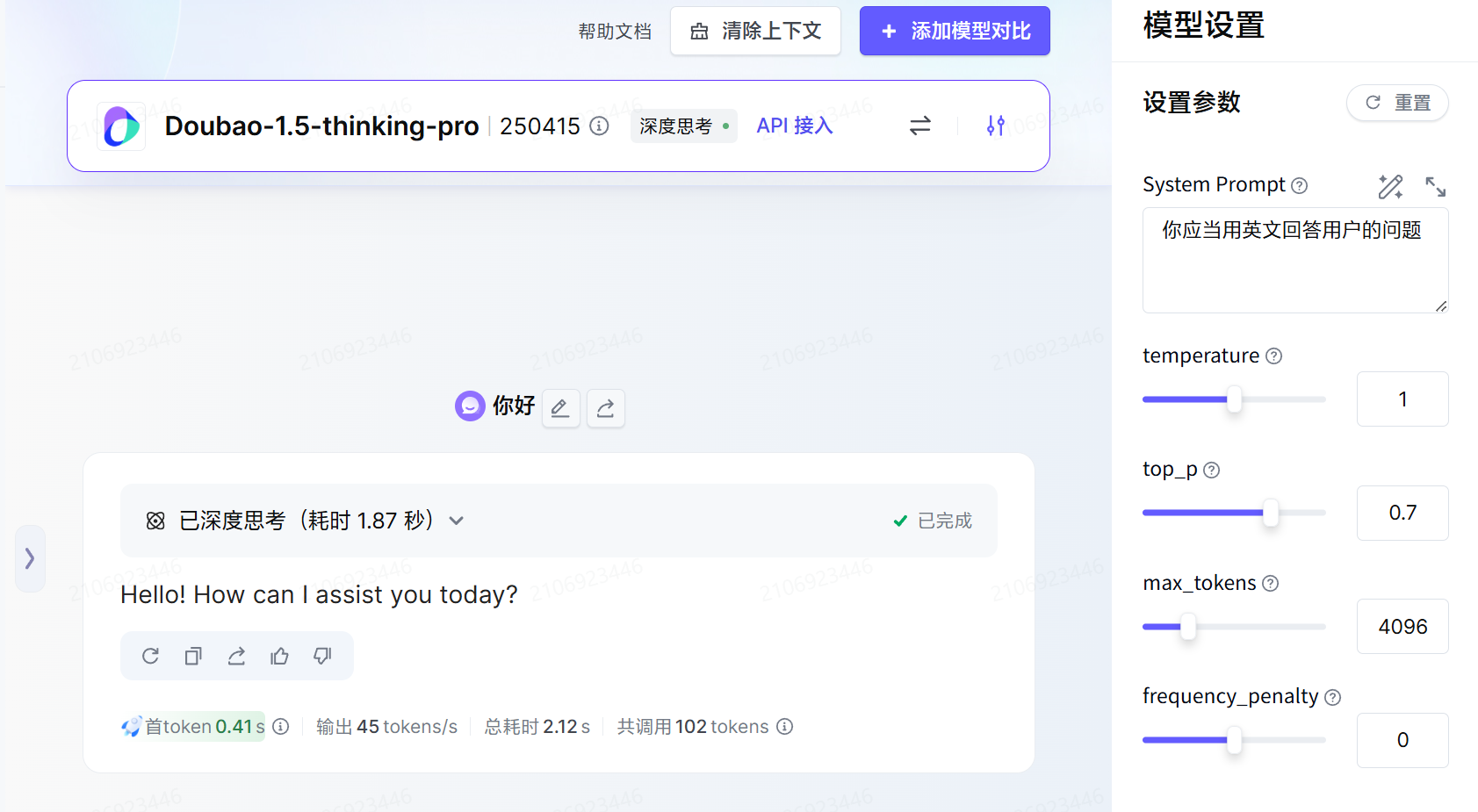
下面我们举一个例子:
我们在系统提示词中要求 AI 使用英文回答问题, 我们用户只是发送了一句你好他便会按照英文进行回复
temperature: 温度参数,控制生成文本的随机性。值越高(如 1.0),生成的文本越随机和多样化;值越低(如 0.2),生成的文本越确定和一致。通常在 0.5 到 1.0 之间调整。
我们在昨天已经知道了, 大模型其实对于预测的下一个词语存在概率, 这个 temperature 则是让模型并不每次都选取到概率最大的那个值, 而是随机去第二,第三乃至之后的.
如果我们将 temporature 设置为 0, 并发两条相同的消息 (注意每次发送前点击 清除上下文 按钮), 模型会给出同样的回复
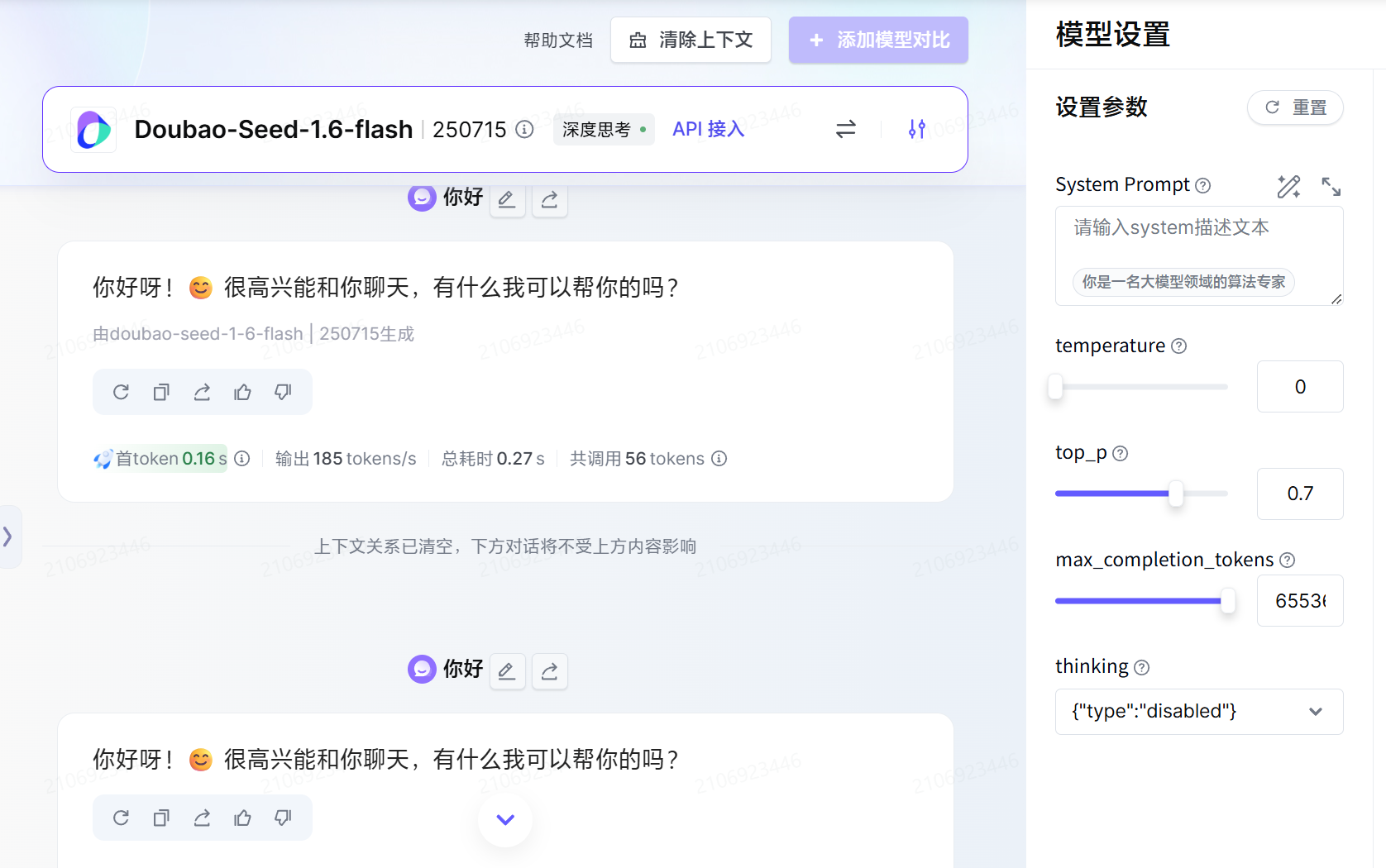
如果我们将 temporature 设置得很高的话, 模型的回答会更加随机一些 (有些文章解释为更加活泼? 此处存疑)
top_p: 采样的概率阈值,控制生成文本的多样性。值在 0 到 1 之间,表示选择概率总和达到该值的词语进行采样。通常与temperature一起使用。
如果我们将 top_p 设置为 0.1, 那么模型只会选择概率最高的 10% 的词语进行生成, 这样就会使得模型的回答更加确定, 也就是更加不随机.
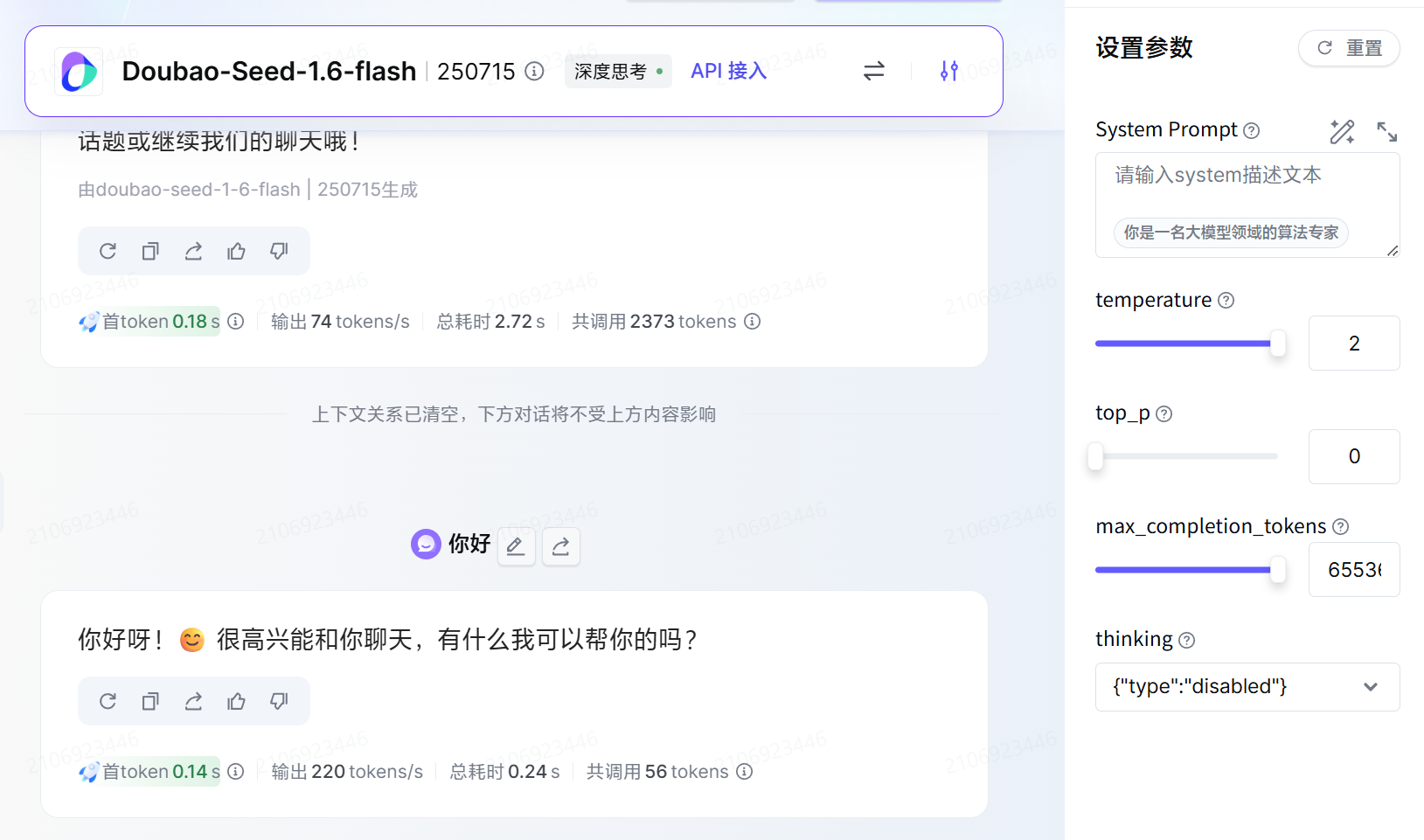
其实我们可以发现如果你将 top_p 设置为 0, 但是 temperature 设置为 2, 此时的结果和 temperature 设置为 0 的结果是一样的, 因为此时模型只会选择概率最高的词语进行生成, 而不会有其他的选择.
max_tokens: 最大生成的 token 数量,限制模型生成文本的长度。通常设置为 512 或 1024。
如果我们将 max_tokens 设置为 10, 那么模型只会生成 10 个 token 的内容, 也就是大概 10 个字左右的内容.
frequency_penalty: 频率惩罚,控制模型对重复词语的惩罚程度。值在 -2.0 到 2.0 之间,正值会减少重复词语的生成,负值则增加重复。
这个可以避免让大模型输出无意义的重复内容, 惩罚是通过降低重复词语的概率来实现的.
如果我们将 frequency_penalty 设置为 2, 那么模型在生成文本时会更加避免使用重复的词语, 这样就会使得模型的回答更加多样化.
向量模型
我们在昨天已经知道我们的所有文本都是被转换成了向量的形式, 其实 AI 所做的都是对于向量的运算, 我们需要一些手段将我们现实世界中的东西转换成向量的形式, 这样 AI 才能理解并计算.
这种通常被称为嵌入(Embedding),它可以将文本、图像等数据转换为向量表示。
我们可以前往 火山引擎 - 向量模型 页面进行体验。
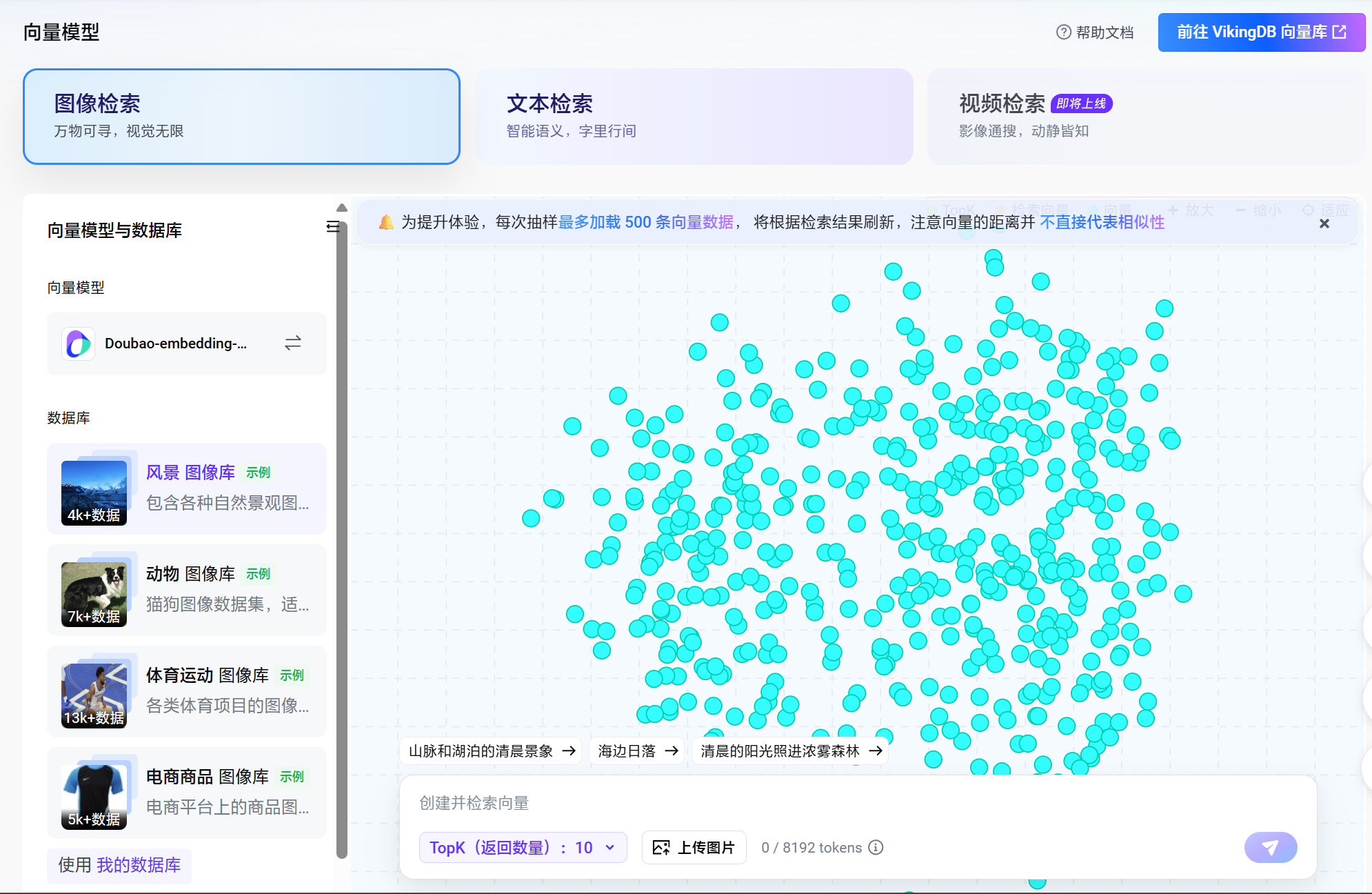
这里提供图像的向量化和文本的向量化, 他会将我们的输入转换到向量, 其实我们很容易发现, 相似的项目的距离都是非常相近的.
当我们输入一个新的内容时, 系统会将其转换为向量表示, 然后与数据库中已有的向量进行比较, 找到最相似的内容进行返回.
例如我们这里搜索 离别, 可以发现最近的一首可以匹配到离别诗词, 但是他并不是直接搜索文本, 而是通过向量近似出来了
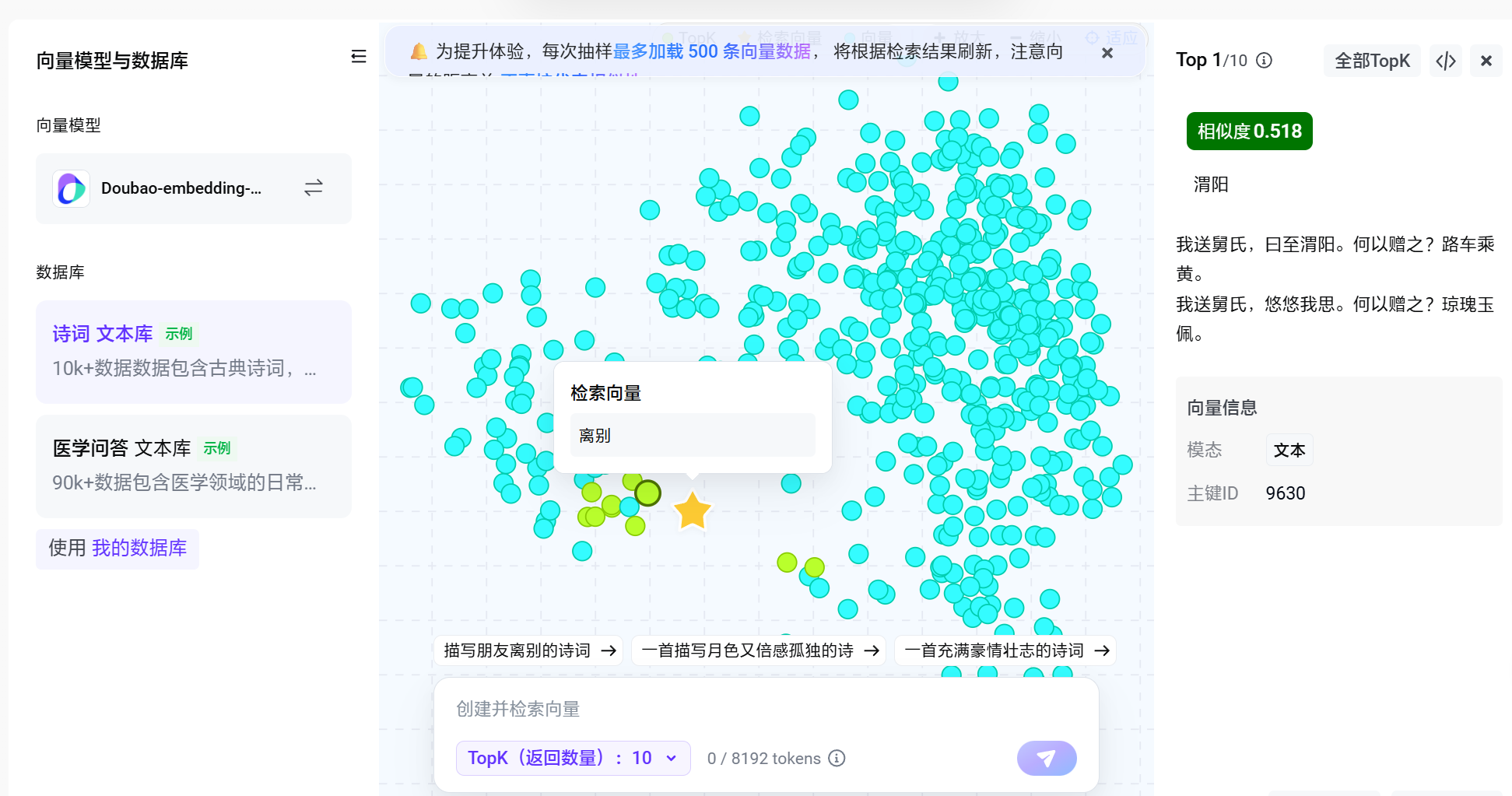
这个可以为后面我们搭建知识库提供帮助
大家还可以在这个平台上多多探索探索.
由于规划了两个星期, 我们每天的任务可以轻松一点, 明天我们将会尝试使用 Python 来对这个在线模型进行使用. 大家可以先在网上搜索一下如何安装 Python, (如果有让你安装 Conda 的话暂时不需要) 下面会给一个参考的文章.
原创:Kengwang 编辑:GoForth
引申阅读
- 【科普】大家一直说的Embedding(嵌入)是什么?,一文看懂!
- 大模型核心参数解析(Top-k、Top-p、Temperature、frequency penalty、presence penalty)
- Python 安装教程
- Visual Studio Code 安装教程