RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与生成式AI的技术,旨在解决大语言模型(LLM)在知识时效性、准确性和领域专业性上的不足。其核心逻辑是:在生成回答前,先从外部知识库中检索与问题相关的信息,再将这些信息作为“参考资料”输入模型,辅助生成更精准、可靠的内容。
通用模型对垂直领域(如医疗、法律)的深度知识有限,模型可能编造不存在的信息,RAG 可接入专业知识库(如医学文献、法规条文),要求回答基于检索到的真实来源,可追溯依据,降低错误率,生成更加准确的回答。
步骤概述
下面将是一步步来对 RAG 的应用步骤进行拆解。
第一阶段:准备数据
我们需要收集目标领域的文本数据,比如文档、网页、论文,格式可以是 PDF、Word、TXT 等。 对于数据我们需要对其进行清理,去除掉重复、无关或低质量内容。 接下来我们还需要对文本进行拆分,通常将长文本切割为短片段(Chunk),每个片段长度在 200-500 字之间,这样可以避免模型处理时遗漏关键信息。因为 RAG 会将这些片段作为检索的目标,所以需要确保每个片段都包含完整的信息。
Tips: 每个数据片段的长度并不是越长越好,过长的文本会导致检索效率降低,且不利于模型理解。需要我们根据实际情况选择一个合适的长度。
第二阶段:构建 RAG 系统
向量嵌入(Embedding)
通过嵌入模型将文本片段转化为高维向量(数值数组),捕捉语义特征。(我们在 Day1 中已经见过了) 语义相似的文本,向量距离更近(如“猫”和“哺乳动物”的向量比“猫”和“汽车”更接近)。
这些向量需要存入到向量数据库中,每一个向量都对应一个文本片段,方便后续检索。
开源的方案比如 Qdrant、Pinecone、Milvus 等,均支持高效的向量存储和检索。
第三阶段:检索与生成
我们在用户发送问题时,首先将问题通过同样的嵌入模型转化为向量,然后在向量数据库中检索与该向量最相似的文本片段(Top-K, 最相似的 K 个向量文本,通常 K=3-5)。我们会将这 K 个文本段同时发送给大语言模型,作为上下文信息,辅助生成回答。
RAG 的优化
目前 RAG 技术已经有了很多成熟的实践,下面给出一些常见的优化方向策略:
- 检索精度提升
- 高级检索策略:结合关键词检索与向量检索,减少语义歧义导致的遗漏。
- 动态拆分:根据文本结构自适应拆分片段,避免关键信息被切断。
- 多模态扩展 传统 RAG 基于文本,目前已扩展到图像、音频等领域. 比如: 用户提问“这张图中的建筑叫什么”,RAG 先将图像转为向量,检索相似图像的标注信息,再生成回答。
- 知识更新机制
- 实时同步:对接数据库或 API 或者一些新闻接口,自动更新知识库。
实践
我们本次尝试在 Cherry Studio 中实践 RAG 技术,我们想要完成一个很简单的任务:
根据已经有的信息,制作一个成都理工大学 计算机与网络安全学院(示范性软件学院)新生指引 AI, 可以让新生询问学校的历史、专业设置、校园设施、报到流程等问题,AI 可以基于已有的信息进行回答。
因为涉及到了很多具体的校园信息,我们需要将这些信息整理成知识库,以便于后续的检索和生成。
第一步:准备数据
我们需要确定来源:
第二步: 处理数据
我们的来源都是纯文本数据, 所以我们只需要复制粘贴即可
我们筛选出如下页面:
我们前往 Cherry Studio 的知识库页面, 点击添加, 输入好知识库名称, 之后选择嵌入模型后确定
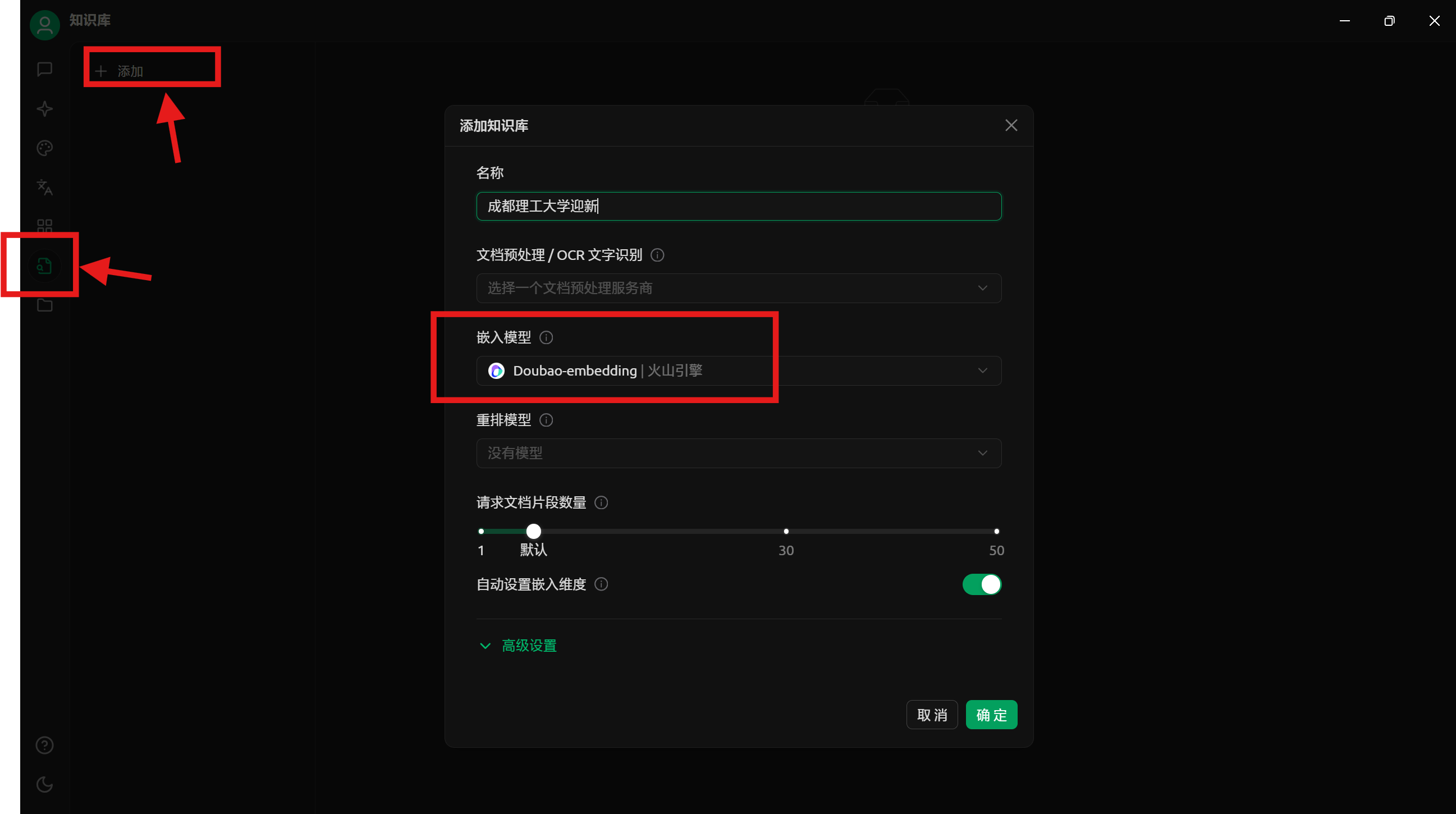
确定后在右边我们可以选择文件导入到知识库, 当然, 我们之前的内容都是纯文本的, 我们可以直接复制网页的内容, 导入纯文本
不建议使用 网址/网站 功能, 有些时候会获取不到内容
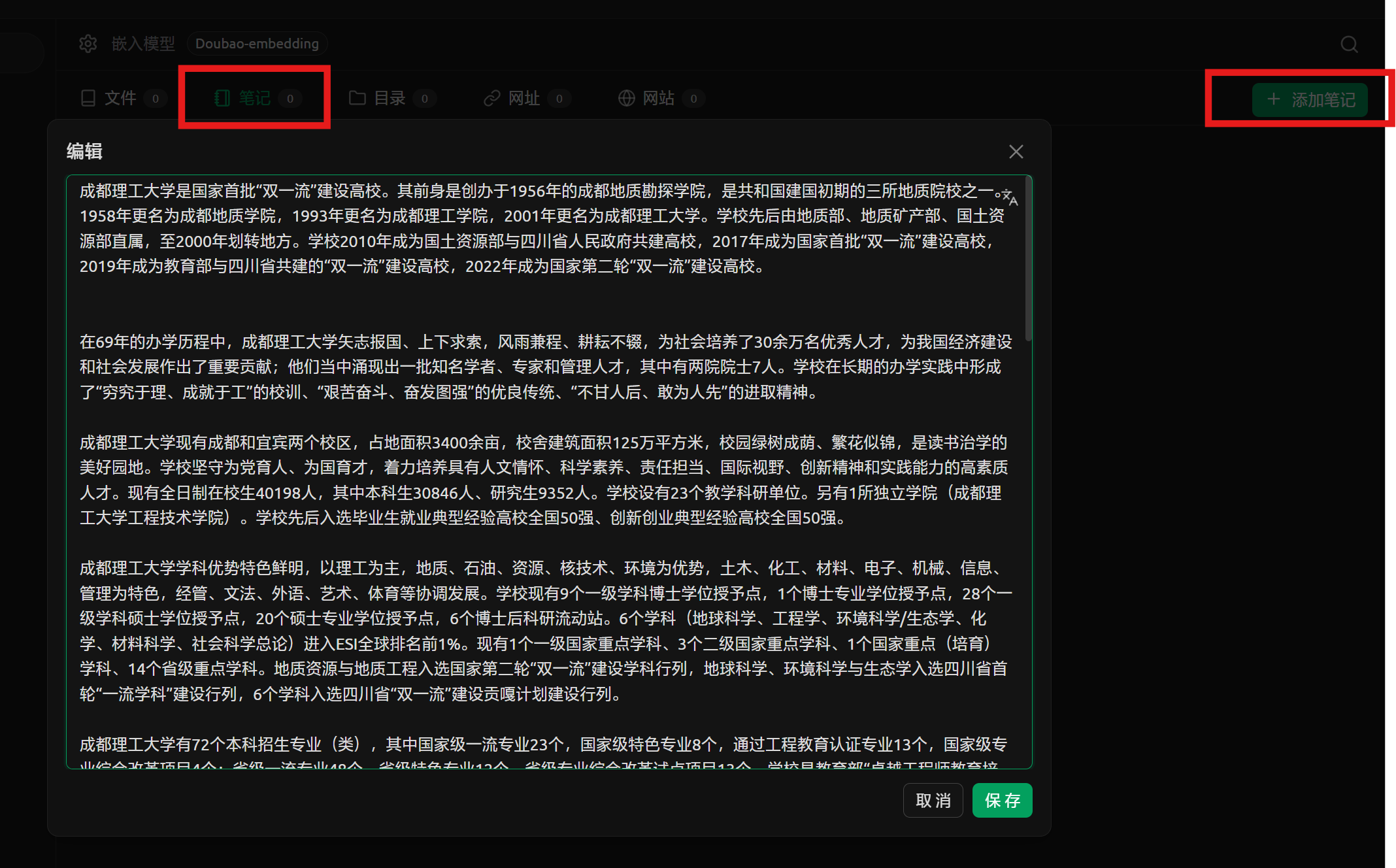
选择笔记选项卡后点击添加笔记, 粘贴网站的内容后点击保存
我们把上面所有网站的内容都给放进去
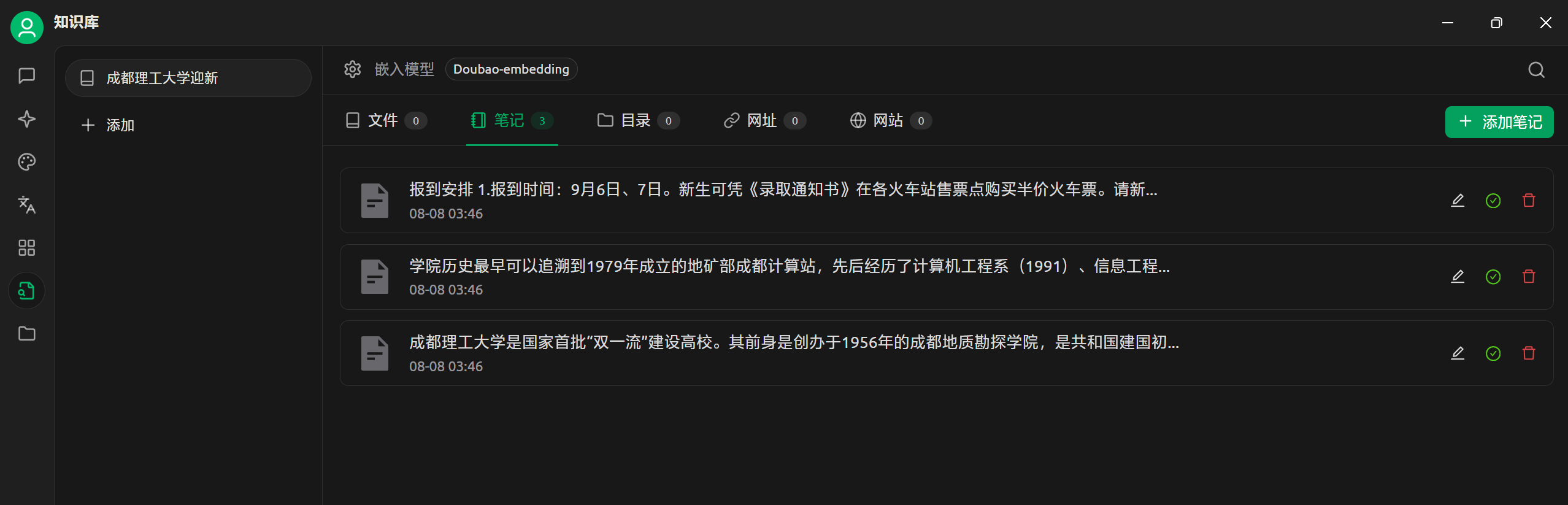
之后我们可以前往聊天框处, 在最左侧的哪个菜单中选择 那个聊天框的按钮 (助手)
再点击新建话题, 在聊天框下方加入我们的知识库

勾选我们刚刚创建的知识库
之后便可以询问 AI 了
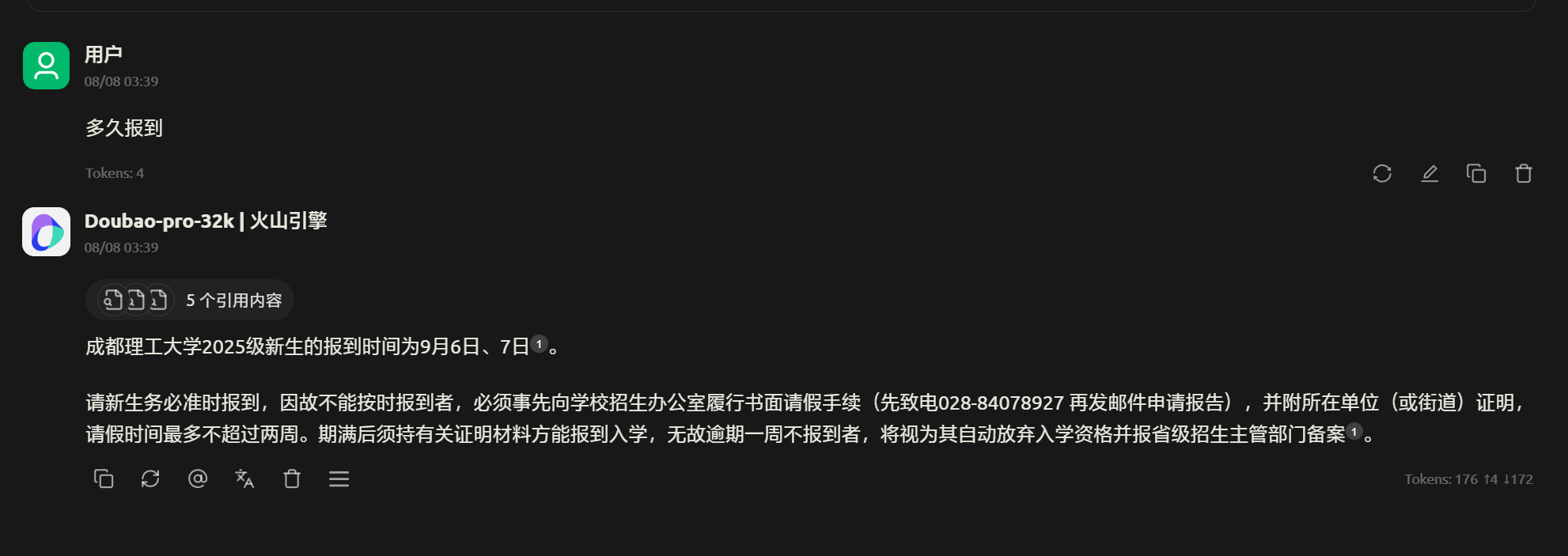
此时 AI 便会引用我们的上下文来进行回答
当然这只是一个示例, 你也可以做一个期末考试帮忙你复习的助手, 将老师的 PPT 资料导入后来询问 AI 问题, 就能防止告诉你错误的知识了
原创:Kengwang 编辑:GoForth
练习
你可以仿照上面自己做一个新生答疑助手, 或者是按照自己的想法做一个例如考试复习助手. 要求需要有显示存在引用内容。