(加载需要一些时间,请耐心等待或浏览下方图文版资料)
什么是知识库?
知识库(Knowledge base)是用于知识管理的一种特殊的数据库,以便于有关领域知识的采集、整理以及提取。知识库中的知识源于领域专家,它是求解问题所需领域知识的集合,包括基本事实、规则和其它有关信息。
知识库的核心特点
- 结构化:
- 知识库通常以一定的逻辑或结构存储知识,包括树形结构、图谱结构、表格或文件存储。
- 例如,将信息分类为主题、子主题,或采用语义网的形式建立知识图谱。
- 查询性:
- 用户可以通过关键字搜索、分类浏览或问答形式,快速找到所需信息。
- 某些知识库还支持自然语言处理(NLP),让用户通过对话方式获取答案。
- 可更新:
- 知识库可以不断新增、修改或移除过时信息,以保持内容的准确性和相关性。
- 交互性:
- 先进的知识库(如智能问答系统)支持用户提问并实时返回答案,甚至能结合上下文提供个性化响应。
误区(点击展开)
很多人想象的AI知识库,就是把所有资料一股脑拖进AI客户端,然后AI就能把里面的内容全部认真读一遍,最后生成一个完美的结论。
实际上并非如此。
按照这样的想法体验后发现,AI知识库的效果并没有想象中那么好,总是遇到各种奇奇怪怪的问题。
那么今天,我们将从知识库的原理出发,探索AI知识库的局限性及其解决办法。
RAG
目前大模型知识库最常用的方法是RAG(Retrieval-Augmented-Generation)也就是检索增强生成。
🔍 RAG 工作原理流程图
当用户把资料添加进知识库的时候,程序会先把它们拆分成很多个文本块,然后使用嵌入模型,对这些文本块进行向量化。
向量化指的是把切分后的文本变成一个超长的数字序列,然后把向量以及对应的文本保存在向量数据库中。
接下来,用户开始提问。不过这个问题并非直接送达大模型那里,而是把问题本身也经过向量化处理,然后把用户的提问与向量数据库进行相似度匹配(这个匹配过程,是基于向量的纯数学运算)最后,知识库选出匹配度最高的几个原文片段,再加上用户的问题发给大模型,大模型进行最后的归纳总结。
🔧 模块说明(可展开)
1. 用户查询(Query)
用户向系统提交问题,例如:
“总结这篇论文核心贡献是什么?”
2. Query Embedding
通过嵌入模型(如 bge-m3)将 Query 转换为向量。
3. 向量数据库检索
使用向量数据库(FAISS、Milvus、Pinecone 等)匹配相似向量并检索 Top-K 文档。
4. 文档重排(可选)
用更加精确的 Reranker(如 bge-reranker)对检索文档重新排序。
5. 上下文准备
进行 chunking、去重、过滤,并构造 prompt。
6. LLM 生成回答
将整理后的上下文注入 LLM 中,以提升回答准确性与可引用性。
7. 反馈与索引
用户反馈可用于更新索引或微调系统。
那么不难看出,大模型仅仅起到一个归纳总结的作用。回答效果的好坏,很大程度上取决于文本块的检索精度。
事实上,RAG系统存在
- 切片很粗暴
- 检索不精准
- 没有大局观
三个经典问题
Cherry Studio
接下来我们先用 Cherry Studio 搭建一个本地知识库,带大家看看这套流程的局限性。
上周已经给大家预告过了,相信大家已经把软件安装好了,现在我们把软件打开,带大家设置一下模型供应商。
本次演示我们使用硅基流动提供的免费模型。
添加知识库
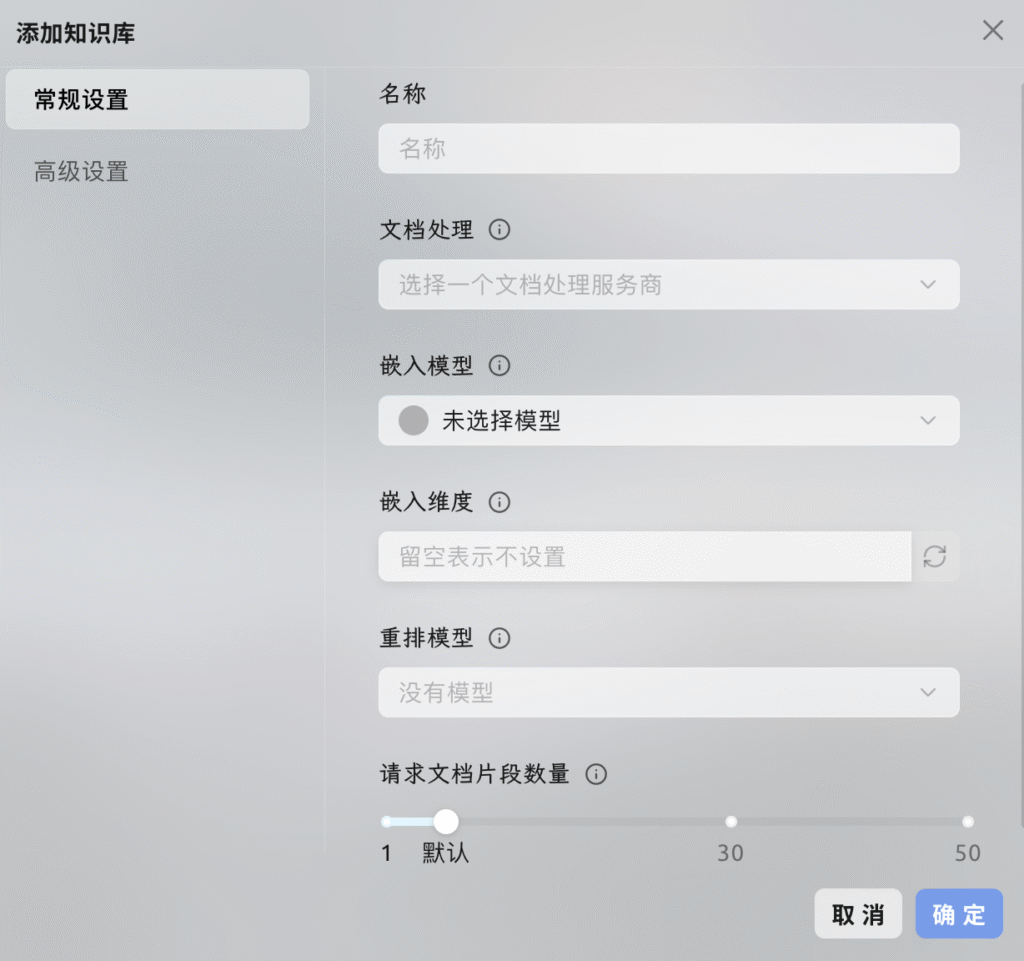
示例文档《三国演义》可以从下方下载
这次先不启用重排序模型
把《三国演义》添加进知识库
知识库数据
在 Cherry Studio 知识库中添加的数据全部存储在本地,在添加过程中会复制一份文档放在 Cherry Studio 数据存储目录
向量数据库:https://turso.tech/libsql
当文档被添加到 Cherry Studio 知识库之后,文件会被切分为若干个片段,然后这些片段会交给嵌入模型进行处理
当使用大模型进行问答的时候,会查询和问题相关的文本片段一并交个大语言模型处理
如果对数据隐私有要求,建议使用本地嵌入数据库和本地大语言模型
我们可以在官方文档中看到,Cherry Studio使用的向量数据库是 Turso 的 libsql
我们回到Cherry Studio,点击右上方的🔍放大镜可以查询对应的分片内容。
比如我这里搜一个“张飞”,通过向量匹配,找出了与张飞有关的段落。
LangChain递归文本分割器
(上方文档可上下滚动)
Cherry Studio使用的分块算法是LangChain的递归文本分割器,这种分块方法比较简单粗暴,基本上等同于按文章段落进行分块。如果段落过长,则按照固定的字数分块。因此句子可能会被拦腰斩断。
句子被腰斩
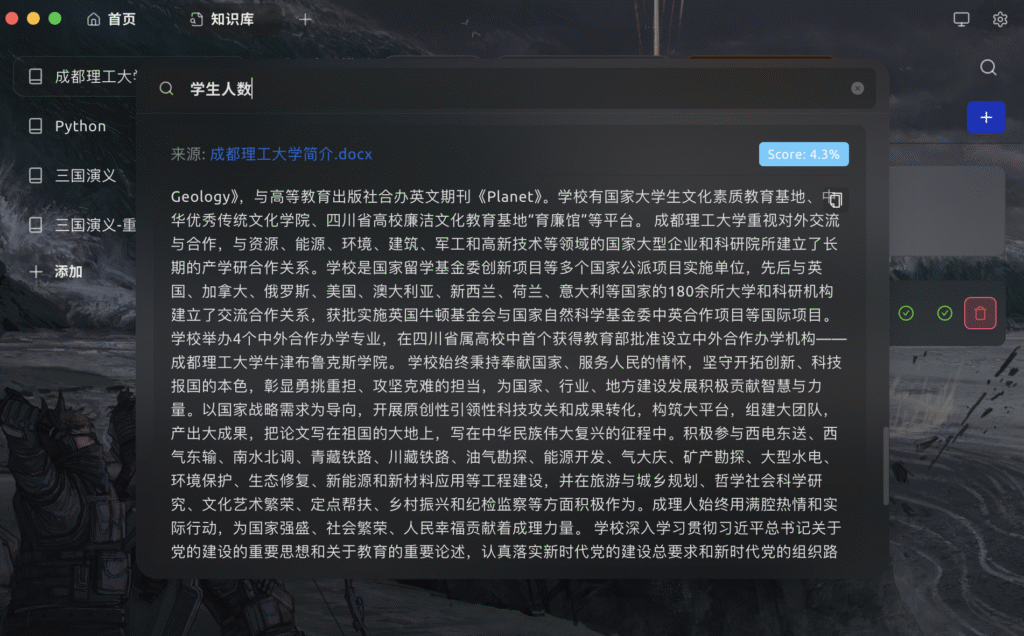
比如我们看这段,开头是Geology加后书名号,明显整个书名都不完整。
由于这段文字达到了分块文字允许的长度上限,句子就会被粗暴地截断。
这是RAG知识库的缺陷之一:切片方法粗暴。
AI大模型拿到这种被拆碎的段落,很难理解上下文的关系,所以输出的回答也不会太精准。
当然,有的同学可能会说,现在也有基于语义分析等等更加复杂的分块切分方法,不过大部分都还不太成熟,很多方法的效果甚至还不如这种简单的分割器。
目前来看,比较有效的方法还是通过人工审核,减少每一分块的长度。
匹配不精准
-1024x634.png)
我们再来看传统RAG的第二个问题,就是检索不精准。
这里我搜索一下“张飞 兵器”,看看能不能找到关于张飞兵器丈八蛇矛的信息。
搜索数据库的时候,是把用户的提问与向量数据库进行匹配,是基于纯数字的相似性计算,并不能代表文字本身的实际含义,所以筛选出来的资料片段,可能跟用户的提问有关,也可能没有关系,没有办法做到完全的精准匹配。
我们看到搜索出来的结果,分数最高,也就是匹配度最高的这个,他跟张飞的武器没有任何关系,然后第2个好像也没什么关系。
从这个例子看出了RAG系统的一大问题,就是向量数据库的匹配不够精准,或者匹配出来的前几条可能都不是我们想要的信息。
使用重排序模型
-1024x634.png)
目前有一种比较好的改进方案,就是使用重排序模型,可以把向量数据库初步检索出来的数据使用专用的重排序模型进行更深入的语义分析,然后再按照问题的相关性进行重新的排序,把相关性最大的一些数据排到前面,并且交付给大模型,这是一种先粗、后细的两步检索策略,可以进一步提高检索精度。
现在我们给这个知识库里加入一个重排序模型bge-reranker-v2-m3,看看效果能不能提升。
接下来回到知识库点击右键,知识库设置我们把重排序模型添加过来,点击确定好我们再来搜索测试一下,还是搜索“张飞 兵器”。
可以看到这次结果大不一样了,出现了“丈八点钢矛”。这次的主要信息排到了第1个,并且分数达到了90%。
这样我们使用了重排序模型,提高了RAG知识库的检索精度。
LM Studio
在讲解第三部分之前,我先给大家演示一下如何使用 LM Studio 自建本地AI语言模型,因为等会儿我们涉及的发给AI的数据量比较大,本地的模型会比在线的稍微好一些。
没有大局观
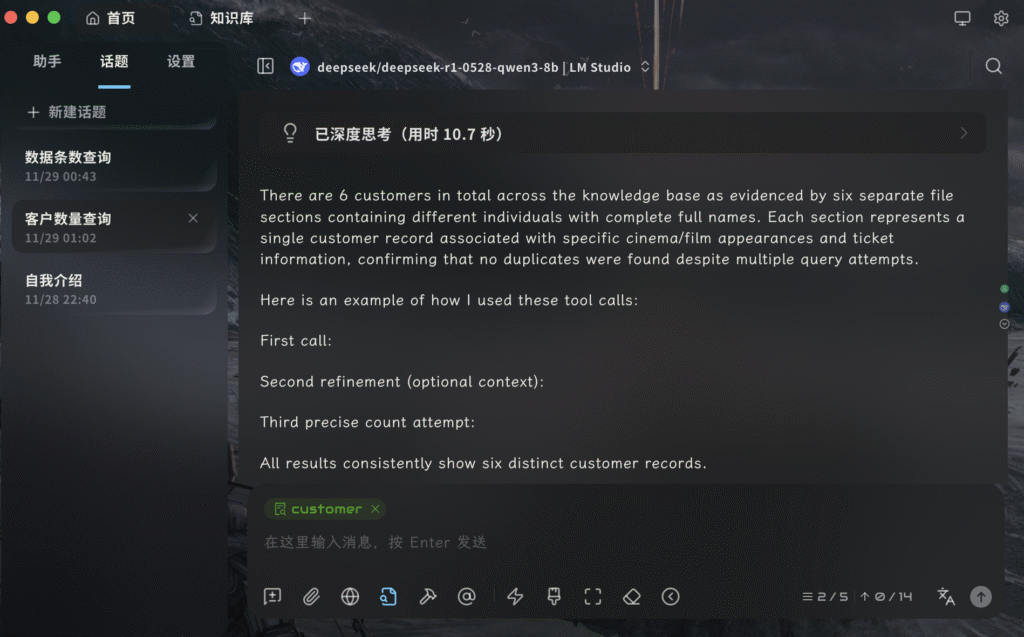
接下来我们来看看RAG的第三个特点:没有大局观
我生成了2万多条顾客的电影购票信息,并存入了Excel表格
如果我们想使用知识库对这里面的数据进行统计分析,RAG技术基本上是无能为力的,因为向量数据库的检索,只是根据相似度匹配文本块,然后把其中的一部分文本交给大模型,这种情况下,大模型根本没有办法根据这些数据碎片做出准确的回答。
我们来试一下。
我新建一个知识库,然后把excel文件添加进去,回到聊天界面问AI有多少个顾客。
不但回答不正确,而且由于数据量过大,把上下文都撑满了。
所以这种结构化的数据,或者这种统计型的问题,使用知识库就根本没办法完成。
面对这种问题,我们最好是使用关系型数据库。
现在有了MCP,让AI使用MCP Server来操作关系型数据库,是一个很好的解决方案。
当然,由于数据库有很多,比如MariaDB、MongoDB、PostgreSQL,不同的数据库需要使用的MCP Server不同。
因为我使用的数据库是MySQL,所以我以MySQL为例给大家演示一下MCP Server的搭建与接入。
基于MCP实现text2sql
教程参考:https://www.cnblogs.com/pam-sh/p/18821579
服务端
选用开源的MySQL MCP Server,本地部署:https://github.com/dpflucas/mysql-mcp-server
# Clone the repository
git clone https://github.com/dpflucas/mysql-mcp-server.git
cd mysql-mcp-server
# Install dependencies and build
npm install
npm run build客户端
使用Cherry Studio作为客户端,内置接入MCP服务器功能。
MCP有两种模式:
- STDIO模式(本地运行)
- 特点:本地安装运行MCP Server,但需配置开发环境。
- 配置步骤:
- 安装依赖:需Python(推荐用uv安装)和NodeJS(推荐bun代替npm),Windows/MacOS/Linux均支持
- 添加MCP服务:在Cherry Studio->Settings->MCP Servers中,选择Edit JSON,填写mcpServers配置内容。
- SSE模式(远程服务)
- 特点:无需本地环境,仅需输入服务器URL,适合调用云端API(如天气查询、数据库接口)。
- 配置步骤:直接输入SSE服务地址即可,例如集成Google Gemini或腾讯混元的联网搜索功能。
添加MCP json:
{
"mcpServers": {
"mysql": {
"isActive": true,
"command": "node",
"args": [
"D:\\code\\MCP\\mysql-mcp-server-main\\build\\index.js"
],
"env": {
"MYSQL_HOST": "localhost",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "root",
"MYSQL_DATABASE": "test"
},
"disabled": false,
"autoApprove": [],
"name": "mysql"
}
}
}这里这样添加的MCP Server是运行在Cherry Studio所在的电脑上,图形化的操作比较方便。
(如果是第一次使用,可能会报uv和bun缺失,点安装按钮进行安装即可)
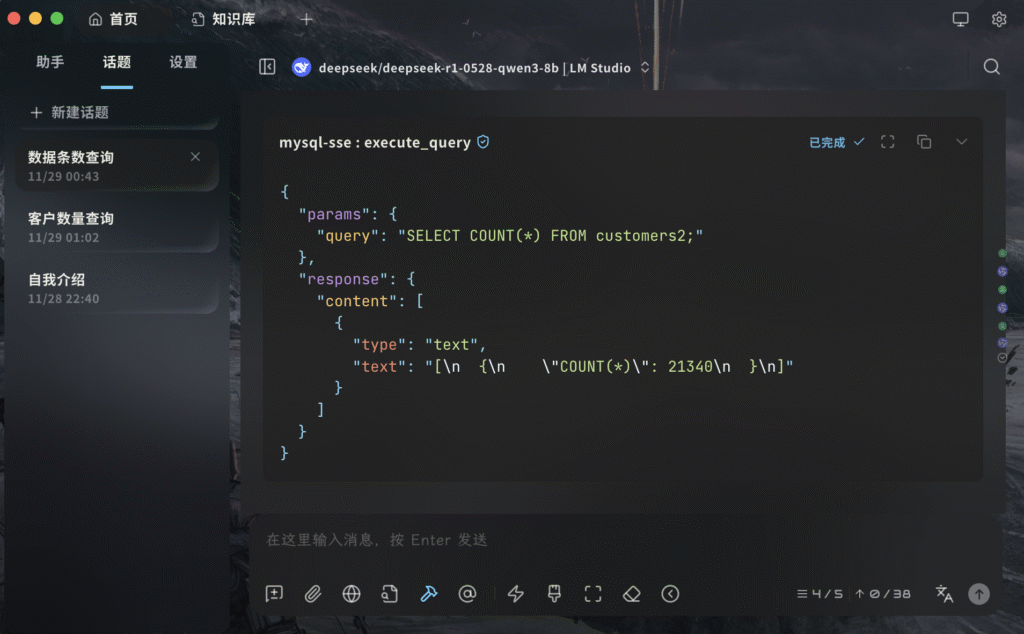
我把刚才的excel表的数据存入了一个MySQL的数据库中,然后让AI调用MCP工具进行查询。
系统提示词:
你是一个数据库助手,你需要调用mysql相关查询工具帮助用户查询数据。以下提供建表的命令以便你了解数据库结构:
CREATE TABLE brookes.customers2 (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
full_name VARCHAR(100),
cinema VARCHAR(100) NOT NULL,
film VARCHAR(100) NOT NULL,
tickets INT NOT NULL CHECK (tickets >= 1),
show_date DATE NOT NULL,
show_time TIME NOT NULL
);问:总共多少个客户
可以看到这个MCP的执行结果是正确的,总共有21340条记录。
其它还可以问:卖了多少张票,最受欢迎的电影院,票房最高的电影,哪天看电影人数最多,人们最喜欢在星期几看电影,数据库中出现了几个名字不同的电影院
总结:我们在这个例子中,使用了MCP Server对接数据库,在查询这种结构化数据的时候,获得了比普通知识库更好的检索效果
一力降十会
使用超长上下文的模型
| 模型 | 参数规模 | 模型架构 | 训练语料规模 | 多模态支持 | 上下文长度 |
|---|---|---|---|---|---|
| ChatGPT (GPT-4) | 未公开(据报道约1万亿参数) | Transformer(可能混合专家) | 未公开(推测数万亿Token) | 文本+图像输入(支持语音输出) | 32K(GPT-4 Turbo版达128K) |
| Claude 3.7 Sonnet | 未公开(估计数千亿级) | Transformer + 混合推理模块 | 未公开(Anthropic未披露) | 文本+图像输入(可解析复杂图表) | 200K (扩展思考模式下128K输出) |
| Gemini 2.5 Pro (Exp) | 未公开(Gemini Ultra据传≈1万亿+) | Transformer + Mixture-of-Experts | 未公开(据称>20万亿Token) | 原生多模态(文本、图像、音频、视频、代码) | 1百万(即将扩展到2百万) |
| DeepSeek V3 | 6850亿总参数(每次激活370亿) | Transformer + 混合专家 (MoE) | 14.8万亿Token | 暂限于文本(未提供视觉/音频) | 128K |
| Grok 3 (xAI) | 2.7万亿参数 | Transformer + 增强推理(深度思考+搜索) | 12.8万亿Token | 文本为主(内置网页搜索引擎) | 128K(支持延长推理时间) |
| QWQ-2.5 Max (Qwen) | 未公开(MoE架构) | Transformer + 混合专家 (MoE) | 20万亿Token | 多模态输出(可生成图像/视频) ;支持网页检索 |
32K(Qwen-2.5-VL模型支持视觉输入) |
| Model | Input Context Window | Approximate Word Count | Approximate Page Count |
|---|---|---|---|
| Gemini 2.0 Pro Experimental | 2,048,576 tokens | ~1,536,000 words | ~5,120 pages |
| Gemini 2.0 Flash | 1,048,576 tokens | ~786,000 words | ~2,620 pages |
| Claude 3 Opus | 200,000 tokens | ~150,000 words | ~500 pages |
| Claude 3.5 Sonnet | 200,000 tokens | ~150,000 words | ~500 pages |
| Claude Instant | 100,000 tokens | ~75,000 words | ~250 pages |
| GPT-4 Turbo | 128,000 tokens | ~96,000 words | ~320 pages |
| Llama 3 | 128,000 tokens | ~96,000 words | ~320 pages |
| Jamba | 256,000 tokens | ~192,000 words | ~640 pages |
| GPT-4 (32k) | 32,768 tokens | ~24,500 words | ~80 pages |
@Autre_planete的帖子 - x.com
除了以上的优化方案,还有一种简单粗暴的方法,就是使用一些超长上下文的模型,把资料直接拖进对话框里,让AI进行检索。
我们在这个表里可以看出,Gemini的上下文窗口长度达到了百万级别,基本上可以容纳整本《三国演义》。
关于Gemini如何使用,之后将由 @GoForth 介绍。